Eksplorowanie bez granic
Dzięki Silnikowi Asocjacyjnemu Qlika użytkownicy mogą swobodnie eksplorować i analizować dane, w dowolnym kierunku, bez ograniczeń zakresu i sposobu analizy.
- Użytkownicy mogą dokonywać selekcji na wszystkich wizualizacjach, tabelach, wykresach i innych obiektach.
- Mogą także użyć wyszukiwania globalnego, aby odkryć powiązania i doprecyzować kontekst analizy.
- Po każdym kliknięciu natychmiast następuje:
– Przeliczanie wszystkich danych analitycznych do nowego kontekstu (stan selekcji).
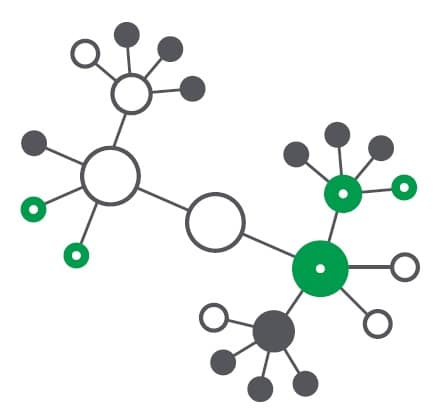
– Podkreślanie skojarzeń w wartościach danych za pomocą kolorów: zielonego (wartości wybrane), białego (wartości powiązane) i szarego (wartości niezwiązane).
Ponieważ Silnik Asocjacyjny Qlika dynamicznie oblicza dane analityczne zamiast wstępnego agregowania danych, użytkownicy mogą płynnie przechodzić do kolejnych zapytań i oglądać nowe, przeliczone na bieżąco zbiory danych. Oznacza to, że każdy użytkownik może zadać dowolne pytanie, na dowolnym poziomie szczegółowości, bez ograniczenia przez predefiniowane zapytania lub hierarchie.
Qlik posiada unikalną i silną funkcję niedostępną w tradycyjnych narzędziach opartych na zapytaniach; nazywamy to „siłą szarości”. Oznacza to, że użytkownicy widzą w swojej analizie nie tylko wartości spełniające ich wybór, ale także niepowiązane dane. Informacje te często prowadzą do niespodziewanych wniosków ukazując na przykład produkty, które się nie sprzedały lub klientów, którzy nie kupili – dając użytkownikom pełny obraz i pomagając im odkryć ukryte obszary możliwości lub ryzyka. W narzędziach opartych na zapytaniach SQL wartości te są odfiltrowywane, przez co użytkownicy mają tylko częściowy zestaw danych i niepełną perspektywę.
W aplikacjach Qlika, za każdym razem, gdy użytkownik dokonuje selekcji lub wykonuje wyszukiwanie, wszystkie wizualizacje, analizy i skojarzenia są natychmiast przeliczane i pokazują aktualny wybór. Wynika to z faktu, że silnik asocjacyjny Qlika obsługuje kontekst, utrzymując stan selekcji dla wszystkich analiz w całej aplikacji.
Funkcjonalność ta daje użytkownikom możliwość zrozumienia wpływu ich selekcji na otaczające analizy na różnych poziomach szczegółowości i z natychmiastowym efektem. Użytkownicy mogą dostrzec potencjalne obszary zainteresowania, zadawać nowe pytania i kontynuować dalsze poszukiwania. Natomiast w przypadku narzędzi opartych na zapytaniach SQL, użytkownicy muszą samodzielnie łączyć obiekty ze sobą i uruchamiać wiele zapytań, aby osiągnąć podobny efekt. Jest to niezwykle pracochłonne i wymaga dużego doświadczenia.